Hey good to see you on our blog post, and welcome to an amazing blog on web scraping tutorials using python. I know that you are eager to make your hands dirty by performing web scraping but before that we should be familiar with web scraping and how it works? Suppose you want some images from a certain website in your local system then you might be copying or downloading each image manually. This is time consuming and cumbersome process. Web scraping makes it easy at your fingertip and automates the process of downloading the data from the web with a few lines of code. The excitement increases at a high level to know more about it so without much waste let's get started and understand web scraping in brief.

Table of Contents
- A brief overview on web scraping?
- Rules and alertness to follow while web scraping
- Hands-on web scraping to scrape images
- End Notes
What is web scraping?
Web scraping is a general term for techniques involved in automating the collection of data from a Website. In simple words, it is a technique to collect and store the data from different websites to your local system or in a database that is used for analysis and driving different business decisions. Today Web scrapping is used by most corporate industries to leverage better decisions in today's competitive market.
👉 Web scraping is used by data scientists, Practitioners to collect the required amount of data to build a well-generalized model. Today there are various service-based companies that provide the data to other big corporates by scraping data through their websites.
👉 By reading the above two paragraphs I hope that you can think of the applications of web scraping and what is its use and how much market this technology has grabbed. It is used in different domains for different purposes like lead generation, marketing, research, testing test cases, etc.
Rules of web scraping
Every website does permit that its data be used by unauthorized users in any means so before performing web scraping you should read about a website, and gain some information about permission and website handling. let s discuss some important rules you should follow and avoid before and while doing web scraping.
- Always try to get permission before scraping.
- If you made too many scraping attempts your IP may be blocked.
- Some sites automatically block scraping software’s so please read about websites first.
Hands-on Web scraping using Python
Prerequisite:
- You must be familiar with the basics of python
- Jupyter IDE installed with you
👉 If you do not have Jupyter IDE then you can also use google Colab or can install Jupyter.
Installing the necessary libraries
Before we start writing a code we must have python web scraping libraries with us. If you are working on the Jupyter notebook of a local system then you can install the below libraries through command prompt or can directly install them in the jupyter notebook also if you are also on google colab then simply type below commands with prefix as an exclamation mark.
pip install requests
pip install bs4
pip install lxml
#If installing in notebooks then write like below
## !pip install lxml
- requests: request module allows you to send an HTTP request to websites using Python.
- lxml: It provides safe and convenient access to these libraries using the ElementTree API.
- bs4: It stands for Beautiful Soup. It is a very important library that enables you to scrape data from the web. It sits at top of an HTML or XML parser which provides pythonic idioms for iterating, searching, and modifying a parse tree.
Learn how to grab images from a websites
Images on a website have their own URL links ending with extensions like .jpg or .png. To scrap the images and demonstrate to you the complete web scraping process to scrape images we will use the Wikipedia website because it is open source.
If you open the Wikipedia page then it is related to chess competition, and we will try grabbing the images of children playing chess, and learn how to scrape any single image as well as multiple images at a time from the web.
Step-1) Import Libraries
Open Jupyter Notebook or the Python IDE where you have installed the libraries and let's start with the code part with loading all the installed libraries.
import requests
import bs4
Step-2) Request website to scrap Images
Now using the python requests module we will make a GET request on a particular page URL so in response to that it will give us a complete HTML source code of that page. But the HTML code is in an encrypted format. To access and extract data from it we need to decrypt it means to apply an HTML parser.
Here we store the result in variable named res, you can use any name you want and request.get("") is the function call-in requests to get the website link and the link is pasted between double inverted commas to get it into our jupyter notebook.
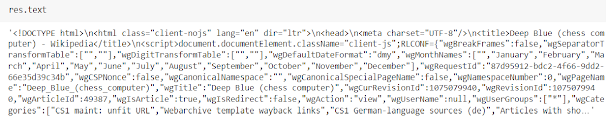
Step-3) Create an object of Beautiful Soap for scraping
soup = bs4.BeautifulSoup(res.text,'lxml')
Here we grabbed BeautifulSoup() from bs4 and pass the link in text format with the library lxml which is a parser to read it, now if you print soup and run it, you will see an HTML document that is scraped from a website.

Step-4) Inspect the Website to Grab the images we want to scrap
In this step, we will be selecting the particular images which we want, For that please visit the website and inspect the images to grab the class or attributes to uniquely identify the image on the website. When you visit the website, just right-click on the image that you want and you can see an option as Inspect, click on it and a developer tools box will open where you can see the code used by a website to place an image on its page.
👉 After inspecting the image You can see that image you are trying to grab is the having a class="thumbimage", so to grab the image, we need to grab this class, so use the following code to do so.
image_info = soup.select('.thumbimage')
Here we grab the image using its class name and the class name is always used with a dot prefix.
Step-5) Grab the source code of the image we want
As there is only one image in the class, we will grab the element(image) by pointing to the zero position in the class.
Step-6) Save the Scraped Image
As we have the source of the image, we can get the image into our jupyter notebook by using the request module. Note that to add HTTP before the scraped source code of the image to get the image correctly from the site.
In your jupyter notebook, you will see a binary file of the image, to save the image in our system we will create a binary file so that we can store the image in it using the below code.
Hence, we have saved the image in our root directory and Now the image is always with you. Now in the same way you can extract Multiple images at a time using a loop.
CONCLUSION
Web Scrapping is a trending technology that is in need of many corporate sectors and I hope that got the feel of the power of web scraping. Now, you can try different methods and loops to extract multiple images at a time and store it in any folder. In our upcoming tutorial, we will also discuss how to extract the text data, time data and create a dataframe so that you can have an exploratory analysis on that.
👉 Thanks to Rishabh Soni for Contributing an amazing article.
happy learning, keep smiling